Reading ML Papers as a newcomer - tips & tricks
I am by no means an expert in ML. However, I am a former consultant and a newcomer to reading ML papers in a program that requires a lot of reading them. So you could say that I am an expert in dealing with complicated content that I am not well versed in ;-) After searching on google for how best to tackle this task it also became rapidly apparent that: 1) reading ML papers is a must for most people in the field, regardless of expertise and 2) a lot of people are intimidated and overwhelmed by it. My favorite comment came from Adam Rubin in ScienceMag:
“Nothing makes you feel stupid quite like reading a scientific journal article”
So, this week I thought I would put down the tips, tricks, hacks & approach that have helped me in tackling ML research papers. Overall the big questions for me were:
How to find good papers to read?
How to prioritize the most important/valuable of these to focus on ?
How to read an individual paper for greatest ROI?
1. How to find papers?
AKA: Is there not just a friendly librarian/ advisor/ wizard to tell me what’s good?
If you find them, send me my way ;-) No, really ….
The key publication sites - most notably arXiv.org - provide online access to papers. One of the truly refreshing things has been how little has been behind paywalls or complicated login systems. arXiv is a repository for preprints - so papers have not been through full peer review cycles. This means that we get very timely access to the latest developments in ML easily (yay!) but on the downside it means that we get ALL the developments - at volume. To be honest I have found arXiv.org too overwhelming generally and have only used it to retrieve specific papers that I have found referenced elsewhere. To search for and find papers I have used the ‘sanity preserver’ arxiv-sanity built by Andrej Karpathy which allows you to curate & sort arXiv by filters like recent, hyped, recommended etc. All the traditional repositories like GoogleScholar and JSTOR include papers but I have found arXiv & arxiv sanity more than enough to access all the papers I have wanted to date. One other publication site that I love is Distill.pub. It is an interactive, visual journal for ML and does not yet suffer from the overwhelm of papers that arXiv does. It has some great papers on visualization, in particular.
Beyond these sources - really using the tips in the prioritization section below has helped me find the papers that I have found most helpful.
2. How to prioritize the most important of these to focus on ?
AKA: Seriously? Do these ML peeps have a 25th hour in the day … there are how many papers out there?
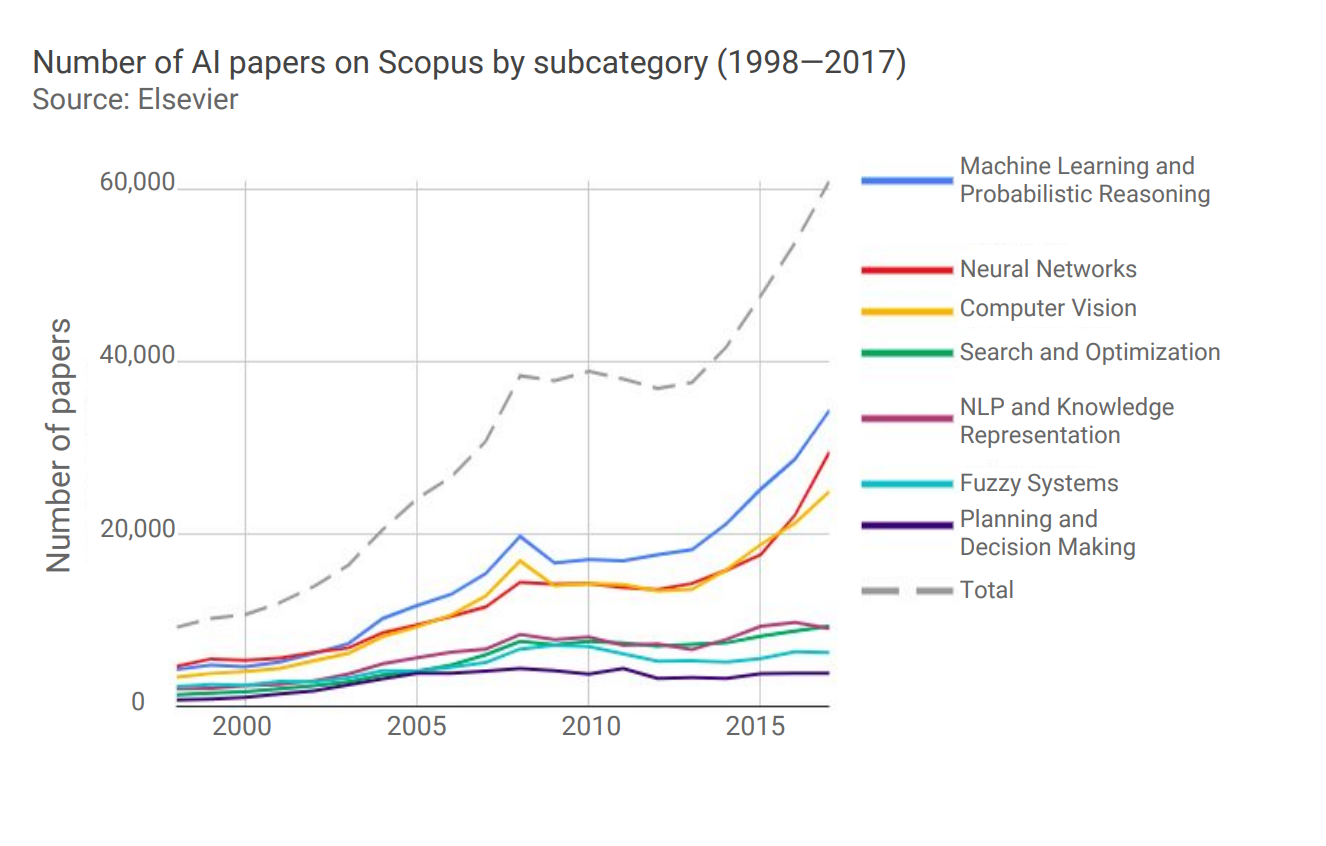
The technical (Australian) term is a shedload… On Friday March 1, 2019 alone 148 new ML papers were published on arXiv; by 2017 more than 60,000 papers in the field of AI were published on the database Scopus (see below). So the problem in ML (or AI/DL as is your wont ) is not a lack of papers, but rather finding a path through the sheer volume of them.
What I have found most helpful in prioritizing papers is to first focus on papers referenced by trusted sources. Looking at the syllabus for famous university classes will reveal the canonical papers for related disciplines (e.g., Stanford’s CS231n & CS224). Moreover the fast.ai DL Course has references to key papers in the field as do a number of comment threads on the associated forum. Papers presented at big conferences in the field (e.g., NeurIPS, CVPR) have all been through an extended vetting process and are a good place to start. (The websites of conference proceedings list papers & sessions.)
Annual year in review posts can be helpful such as ”Top ML Papers of 2018” - whether rolled up on Reddit* comment threads or blogs like TopBots. And following key people on Twitter can surface new papers of note on a more rolling basis (for instance Jeremy Howard of fast.ai, Jason Brownlee etc).
For specific topic areas that I am interested in, I have had luck searching out datasets on Kaggle - often the datasets come from a paper that you can then reference back to read.
*Note on Reddit - I have found the ML & related channels very helpful, the content broadly reliable and the discussion mostly civil which is refreshingly different to many other parts of that site.
3. How to read an individual paper for greatest ROI?
AKA: OK, so now I have a bunch of greek letters in front of me …
A lot of the advice I read online in regard this topic felt a little …. unhelpful. “Start with the Abstract or Introduction!” - Frankly I would love to meet someone who googled ‘how to read academic ML journals’ and whose instinctive approach to a complex scientific paper is to say “screw the intro - what use could that possibly be to me!?” What I found most helpful was a walkthrough of a specific paper and how to think about reading it most efficiently to 1) Understand the importance of its findings & its implementation/architecture and 2) Decide if it was worth returning to read again at a more detailed level. This kind of walk through is a part of CS230 and I am including my interpretation of such an approach below using the original YOLO Paper as an example:

-> Start with the Abstract/Intro(!) & list out the key points:
This is a new object detection approach
It’s extremely fast, but prone to more localization problems than alternatives
It frames localization as a regression task & needs only one pass to achieve localization & classification
-> Check the conclusion for anything different/additional to abstract:
Nothing different
-> Look at the figures as an efficient way to understand methodology & high level details:
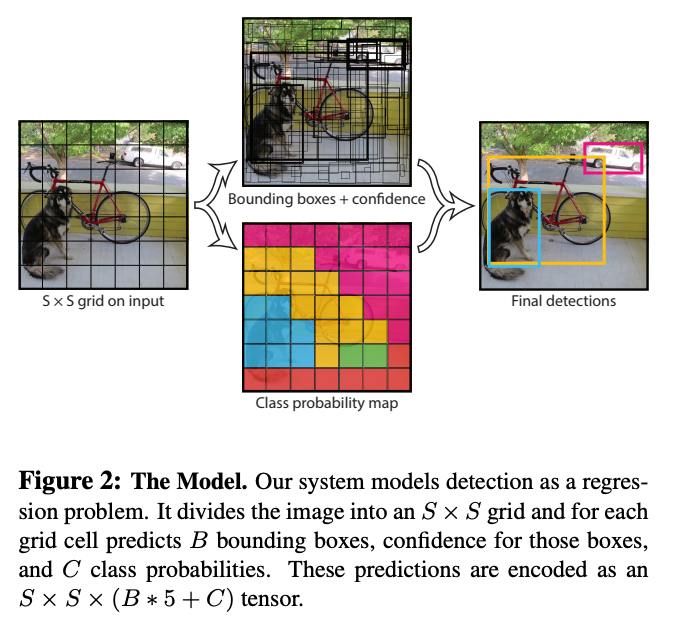
Fig 1: Yolo takes 3 steps to identify objects -
1) Resize images for CNN
2) Run them through CNN
3) Use Non Max Suppression to deliver bounding boxes with objects & class probabilities
- Note for myself - As I understand 1 &2 but not ‘non max suppression’ if I want to read this paper in detail later I will definitely need to come back to this point, but move on for nowFig 2: Yolo creates a grid of SxS over the input image & performs classification in each of these grid squares (can see on the multi-color map). But the note says that predictions are encoded as output=SxSx(B*5+C) tensor. B represents bounding boxes but why is it multiplied by 5? Scanning the prior para quickly you can see that the grid boxes are defined in terms of their central point (x,y coords), height and width which is only 4 numbers to multiply by. The fifth is a confidence score representing how confident the model is that an object exists in the bounding box.
Fig 3: The architecture - this shows that it as Conv net, that the output is ultimately:
SxSx(B5+C) = 7 * 7 * 30 & that there is a flattening step immediately prior to the output tensorLoss Function - see notes below
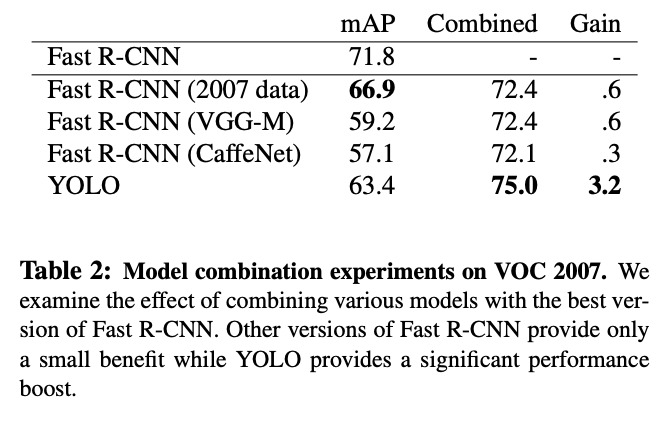
Table 1 & Fig 4: Error Analysis shows that while Yolo is fastest on record for Pascal VOC it lags in terms of localization accuracy by a factor of 2X.



-> Try to find the loss function quickly & get a feel for the optimization:
This loss function is split into 5 lines, each line representing a term in loss function - try to work out what each term is doing:
- T1: localization term - if there is an object in I,j square then predict the center of the box (x,y) vs ground truth - penalizes bad localization of center of boxes
- T2: localization term - if there is an object find width and height error, use square root as care about the ratio (i.e. penalize errors in small boxes more as we need greater accuracy in smaller bounding boxes)
- T3: measure the confidence - confidence that there is an object in the bounding box (0/1 in ground truth);
- T4: “lambda no object” multiplied by difference in confidence squared- how much weight to assign to bounding box if no object in it. Essentially penalize false positives (where bounding box has no object in it)
- T5: classification - not cross-entropy loss interestingly, they use square error

-> Based on this decide if you want to read further or save for later:
If you are interested in object detection but require very high accuracy; or if you are simply not interested in object detection then there are likely other papers to focus on in depth that will give you higher ROI
However if you are focused on speed & object detection then it is likely a good paper to focus on so go back and read the paper now. ..
So what?
AKA: You realize you have been asking yourself these questions, isn’t that the first sign of …
At the end of the day there is no substitute for practice - as one reddit user put it:
you learn how to read a machine learning conference paper effectively the same way you learn how to do anything else, practice. if you want to become more literate, you have to read more, it really is that simple.
virtualreservoir on Reddit
However, when starting out with ML papers it can be very difficult to ‘just read more’ and I have found that selecting papers carefully and using the tips/tricks/hacks/shortcuts/your-choice-of-word as above have helped me alot in not giving up or just skimming over papers that deserve my attention.
I will add that some great original help on this came from CS230, CS231n as well as comment threads on Reddit (such as here and here ), as well as blog posts (like this and this).